Spark Connect
This page explains the Spark Connect architecture, the benefits of Spark Connect, and how to upgrade to Spark Connect.
Let’s start by exploring the architecture of Spark Connect at a high level.
High-level Spark Connect architecture
Spark Connect is a protocol that specifies how a client application can communicate with a remote Spark Server. Clients that implement the Spark Connect protocol can connect and make requests to remote Spark Servers, very similar to how client applications can connect to databases using a JDBC driver - a query spark.table("some_table").limit(5) should simply return the result. This architecture gives end users a great developer experience.
Here’s how Spark Connect works at a high level:
- A connection is established between the Client and Spark Server
- The Client converts a DataFrame query to an unresolved logical plan that describes the intent of the operation rather than how it should be executed
- The unresolved logical plan is encoded and sent to the Spark Server
- The Spark Server optimizes and runs the query
- The Spark Server sends the results back to the Client
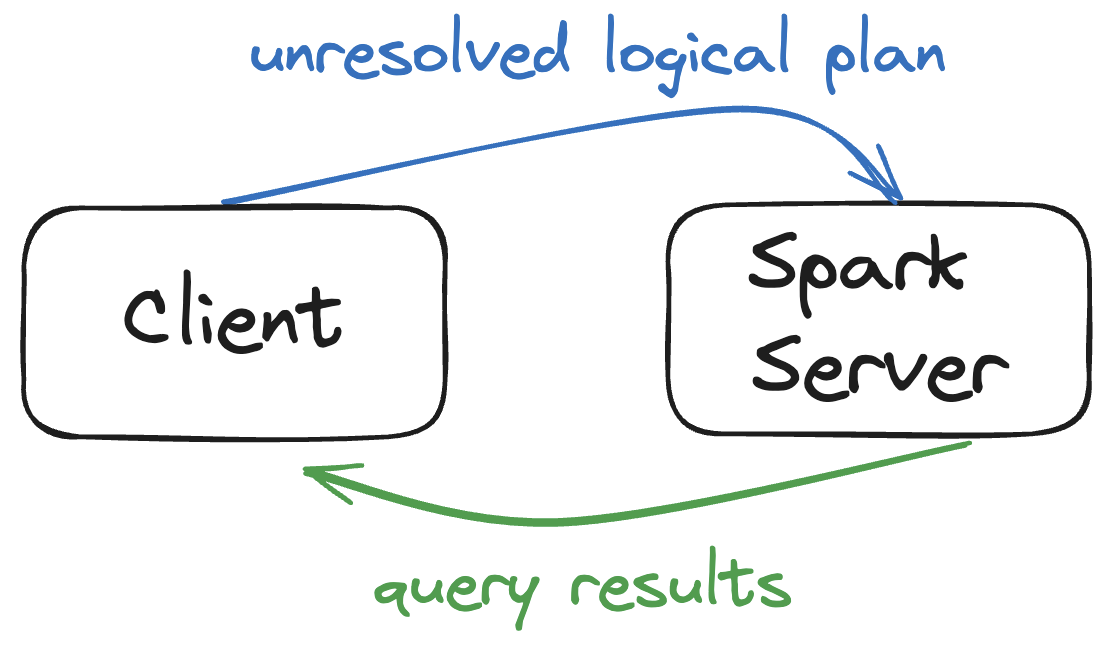
Let’s go through these steps in more detail to get a better understanding of the inner workings of Spark Connect.
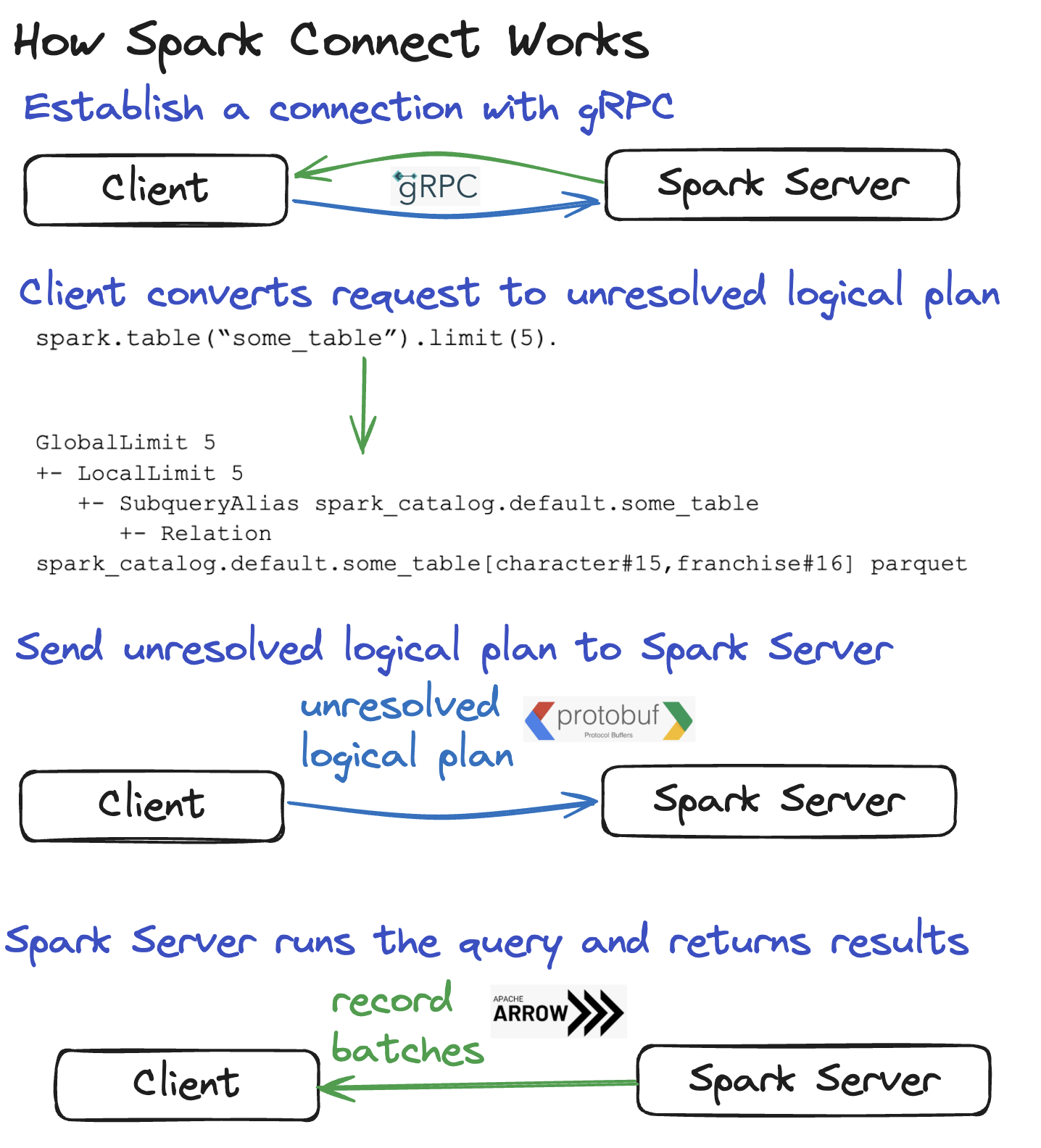
Establishing a connection between the Client and the Spark Server
The network communication for Spark Connect uses the gRPC framework.
gRPC is performant and language agnostic which makes Spark Connect portable.
Converting a DataFrame query to an unresolved logical plan
The Client parses DataFrame queries and converts them to unresolved logical plans.
Suppose you have the following DataFrame query: spark.table("some_table").limit(5).
Here’s the unresolved logical plan for the query:
== Parsed Logical Plan ==
GlobalLimit 5
+- LocalLimit 5
+- SubqueryAlias spark_catalog.default.some_table
+- UnresolvedRelation spark_catalog.default.some_table
The Client is responsible for creating the unresolved logical plan and passing it to the Spark Server for execution.
Sending the unresolved logical plan to the Spark Server
The unresolved logical plan must be serialized so it can be sent over a network. Spark Connect uses Protocol Buffers, which are “language-neutral, platform-neutral extensible mechanisms for serializing structured data”.
The Client and the Spark Server must be able to communicate with a language-neutral format like Protocol Buffers because they might be using different programming languages or different software versions.
Now let’s look at how the Spark Server executes the query.
Executing the query on the Spark Server
The Spark Server receives the unresolved logical plan (once the Protocol Buffer is deserialized) and analyzes, optimizes, and executes it just like any other query.
Spark performs many optimizations to an unresolved logical plan before executing the query. All of these optimizations happen on the Spark Server and are independent of the client application.
Spark Connect lets you leverage Spark’s powerful query optimization capabilities, even with Clients that don’t depend on Spark or the JVM.
Sending the results back to the Client
The Spark Server sends the results back to the Client after executing the query.
The results are sent to the client as Apache Arrow record batches. A single record batch includes many rows of data.
The full result is streamed to the client in partial chunks of record batches, not all at once. Streaming the results from the Spark Server to the Client prevents memory issues caused by an excessively large request.
Here’s a recap of how Spark Connect works in image form:
Benefits of Spark Connect
Let’s now turn our attention to the benefits of the Spark Connect architecture.
Spark Connect workloads are easier to maintain
When you do not use Spark Connect, the client and Spark Driver must run identical software versions. They need the same Java, Scala, and other dependency versions. Suppose you develop a Spark project on your local machine, package it as a JAR file, and deploy it in the cloud to run on a production dataset. You need to build the JAR file on your local machine with the same dependencies used in the cloud. If you compile the JAR file with Scala 2.13, you must also provision the cluster with a Spark JAR compiled with Scala 2.13.
Suppose you are building your JAR with Scala 2.12, and your cloud provider releases a new runtime built with Scala 2.13. When you don’t use Spark Connect, you need to update your project locally, which may be challenging. For example, when you update your project to Scala 2.13, you must also upgrade all the project dependencies (and transitive dependencies) to Scala 2.13. If some of those JAR files don’t exist, you can’t upgrade.
In contrast, Spark Connect decouples the client and the Spark Driver, so you can update the Spark Driver including server-side dependencies without updating the client. This makes Spark projects much easier to maintain. In particular, for pure Python workloads, decoupling Python from the Java dependency on the client improves the overall user experience with Apache Spark.
Spark Connect lets you build Spark Connect Clients in non-JVM languages
Spark Connect decouples the client and the Spark Driver so that you can write a Spark Connect Client in any language. Here are some Spark Connect Clients that don’t depend on Java/Scala:
- Spark Connect Python
- Spark Connect Go
- Spark Connect Rust
- Spark Connect Swift
- Spark Connect .NET (third-party project)
For example, the Apache Spark Connect Client for Golang, spark-connect-go, implements the Spark Connect protocol and does not rely on Java. You can use this Spark Connect Client to develop Spark applications with Go without installing Java or Spark.
Here’s how to execute a query with the Go programming language using spark-connect-go:
spark, _ := sql.SparkSession.Builder.Remote(remote).Build()
df, _ := spark.Sql("select * from my_cool_table where age > 42")
df.Show(100, false)
When df.Show() is invoked, spark-connect-go processes the query into an unresolved logical plan and sends it to the Spark Driver for execution.
spark-connect-go is a magnificent example of how the decoupled nature of Spark Connect allows for a better end-user experience.
Go isn’t the only language that will benefit from this architecture.
Spark Connect allows for better remote development and testing
Spark Connect also enables you to embed Spark in text editors on remote clusters without SSH (“remote development”).
When you do not use Spark Connect, embedding Spark in text editors with Spark requires a Spark Session running locally or an SSH connection to a remote Spark Driver.
Spark Connect lets you connect to a remote Spark Driver with a connection that’s fully embedded in a text editor without SSH. This provides users with a better experience when developing code in a text editor like VS Code on a remote Spark cluster.
With Spark Connect, switching from a local Spark Session to a remote Spark Session is easy - it’s just a matter of changing the connection string.
Spark Connect makes debugging easier
Spark Connect lets you connect your text editor like IntelliJ to a remote Spark cluster and step through your code with a debugger. You can debug an application running on a production dataset, just like you would for a test dataset on your local machine. This gives you a great developer experience, especially when you want to leverage high-quality debugging tools built into IDEs.
Spark JVM does not allow for this debugging experience because it does not fully integrate with text editors. Spark Connect allows you to build tight integrations in text editors with the wonderful debugging experience for remote Spark workflows. By simply switching the connection string for the Spark Connect session it becomes easy to configure the client to run tests in different execution environments without deploying a complicated Spark application.
Spark Connect is more stable
Due to the decoupled nature of client applications leveraging Spark Connect, failures of the client are now decoupled from the Spark Driver. This means that when a client application fails, its failure modes are completely independent of the other applications and don’t impact the running Spark Driver that may continue serving other client applications.
Upgrading to Spark Connect
Spark Connect does not support all the Spark JVM APIs. For example, Spark JVM has private methods that some users leverage to execute arbitrary Java code on Spark clusters. Spark Connect obviously cannot support those methods because the Spark Connect client isn’t necessarily running Java!
Check out the guide on migrating from Spark JVM to Spark Connect to learn more about how to write code that works with Spark Connect. Also, check out how to build Spark Connect custom extensions to learn how to use specialized logic.
Conclusion
Spark Connect is a better architecture for running Spark in production settings. It’s more flexible, easier to maintain, and provides a better developer experience.
Migrating some Spark JVM codebases to Spark Connect is easy, but the migration is challenging for other codebases. Codebases that leverage the RDD API or use private Spark JVM functions are more challenging to migrate.
However, migrating from Spark JVM to Spark Connect is a one-time cost, so you will enjoy all the benefits once you migrate.
Latest News
- Spark 3.5.9 released (Jul 16, 2026)
- Spark 4.1.3 released (Jul 15, 2026)
- Spark 4.0.4 released (Jul 15, 2026)
- Spark 4.2.0 released (Jul 14, 2026)
